Introduction
Missing logs can be a thorn in the side for many Kubernetes users. In this article, we dive into why this happens and how to prevent it.
I have been investigating the case of missing Kubernetes logs in Elasticsearch, which in my case, aggregates logs for Kubernetes pods. I’m running a standard setup of Elasticsearch and Fluentd, and every now and then, there is a gap in Elasticsearch with no logs for a couple of seconds.
To better understand what is going on, let’s start from the very beginning:
- First, let’s know how container logging is managed by Container Runtimes like Docker, Containerd, and CRI-O.
- Secondly, let’s look at how Kubelet handles logs together with Container Runtime.
- Thirdly, let’s see what the actual issue with Fluentd was
How Container Runtimes handle logging
In Kubernetes, there are two cases to cover for Container Runtime logging. One is Docker runtime, which is deprecated. The other one is CRI-based implementation, such as Containerd or CRI-O.
Let’s start with Docker.
How Docker handles logging
If you are running Kubernetes with Docker, you can configure various logging drivers. Docker has different direct integrations with Fluentd, Journald, etc. But as you are running Kubernetes and adding application metadata to the logs, you need to use a JSON file logging driver. JSON-file logging driver writes JSON formatted log files into:
/var/lib/containers/$containerID/$containerID-json.log. You typically configure log rotation to avoid filling up the hard drive with logs. For example, in Docker, you can enable log rotation by editing `/etc/docker/daemon.json` file and changing `max-file` and `max-size` parameters. Here is an example of Docker configuration:
{
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "2"
}
}This configuration will make Docker rotate logs once a file hits ten Mb in size and keep two log files. The oldest file gets removed once the third log rotation happens.
When Docker rotates a file, the rotated files get renamed with a numerical postfix. So if the original file is /var/lib/containers/$containerID/$containerID-json.log, the rotated file will be available at /var/lib/containers/$containerID/$containerID-json.log.1. The postfix gets incremented based on the age of the file and `max-file` parameter.
That’s the gist of how Docker runtime handles logging. Now let’s take a look at CRI-based implementations.
How Containerd and CRI-O handle logging
Interestingly, in CRI-based implementations, logging is handled very differently. For example, you can’t configure Containerd or CRI-O to change the logging directory or log rotation parameters. It might be weird, but it turns out that the log path is part of the “create new pod” request in CRI spec.
So in the Kubernetes world, this means that when Kubelet needs to run a new Pod, it tells Container Runtime daemon where to store the logs. Kubelet achieves this via CRI’s `RunPodSandbox` and `CreateContainer` GRPC methods. For `RunPodSandbox`, Kubelet sets PodSandboxConfig.LogDirectory request parameter to:
/var/log/pods/$podNamespace_$podName_$podUIDAnd when calling the CreateContainer request, it uses the sets ContainerConfig.LogPath to be:
$containerName/$restartCount.logSo, Kubelet tells CRI where and how to store the logs. Because Kubernetes handles the logging, it is also responsible for log rotation. To configure log rotation, you need to configure Kubelet’s `containerLogMaxFiles` and `containerLogMaxFiles` configuration parameters. Usually, you can set it in `/var/lib/kubelet/config.yaml`.
Let’s take a look at an example configuration:
containerLogMaxFiles: 3
containerLogMaxSize: 2MiThis configuration makes Kubelet rotate a file after reaching two Mb in size and keeping three rotated files. In addition, Kubelet adds a date and a numeric postfix to rotated files, and the third turned file gets gzipped. Here is an example of actual log files with log rotation enabled:
cd /var/log/pods/kube-system_test-pod_3321855e-568b-4fe8-9bc2-549a846c309e/test-pod
ls -ltrahdrwxr-xr-x 3 root root 4.0K Mar 4 09:29 ..
-rw-r--r-- 1 root root 330K Mar 4 09:30 0.log.20210304-092951.gz
-rw-r----- 1 root root 5.2M Mar 4 09:30 0.log.20210304-093002
drwxr-xr-x 2 root root 4.0K Mar 4 09:30 .
-rw-r----- 1 root root 4.7M Mar 4 09:30 0.logAnother interesting detail is that CRI does not log in JSON format. Instead, it has its custom log format, which looks like this:
2016-10-06T00:17:09.669794202Z stdout The content of the log entry 1
2016-10-06T00:17:10.113242941Z stderr The content of the log entry 2Those are the crucial bits of CRI-based logging. Now let’s look at some additional interesting quirks around Kubelet logging interactions.
Kubelet logging interactions
If you have been running Kubernetes for a while, you will know you can get container logs in /var/log/containers/*. But how do these files get created?
You know from previous paragraphs that Docker and CRI will not place logs there.
Kubelet creates a bunch of standard symlinks before starting Pod up.
/var/log/containers/$podName_$namespace_$containerName-$containerID.log, which will point to the latest log file in/var/log/pods/$podNamespace_$podName_$podUID/$containerName/$restartCount.log.- When using Docker additional symlink from
/var/log/pods/$podNamespace_$podName_$podUID/$containerName/$restartCount.logto/var/lib/containers/$containerID/$containerID-json.logis created.
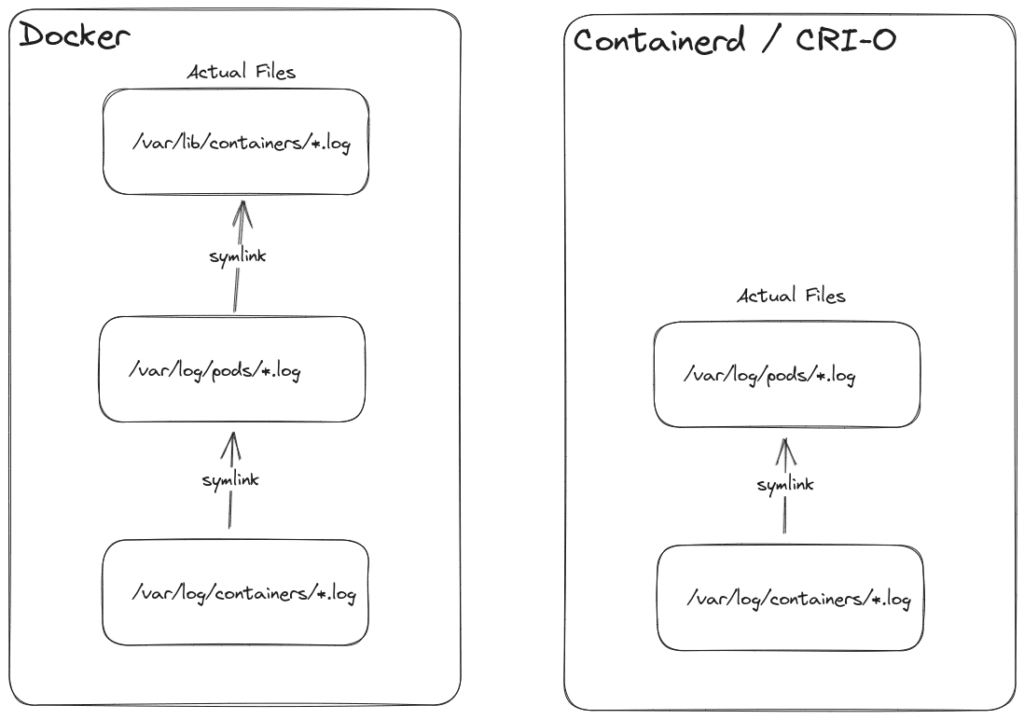
It’s important to note that symlinks point to the latest non-rotated file. Importantly this means – if you read logs from /var/log/containers, you won’t see rotated log files.
Log Aggregators
For log aggregation to work reliably, the log aggregator daemon needs to read logs from either /var/log/pods/* for CRI runtime or /var/lib/docker/* for Docker runtime, as these paths have actual log files with rotated logs. Additionally, you need to configure either Kubelet or Docker to keep at least two files.
If the log aggregator reads from /var/log/containers, there is a high probability that you will lose logs. A typical scenario is Elasticsearch delays responding to a batch index request, making the log daemon back off reading logs. If, during that time, the container log rotates over, you lose logs. Another typical scenario is log daemon upgrades. If the container log rotates during the shutdown, you will lose logs.
Now let’s look at the actual issue I had with Fluentd.
Fluentd
One of the most popular in the Kubernetes ecosystem is the Fluentd log aggregator. Fluentd installation is easy, and the project has a pre-made Daemon set configuration. To parse Kubernetes Pods logs and add Kubernetes metadata to logs, Fluentd uses the fluent-plugin-kubernetes_metadata_filter plugin. This plugin parses the log path structure and queries Kubernetes API Server to get more metadata.
Well, in my case, I was losing logs because I was running an old version of this plugin, which read and parsed the logs from /var/log/containers.
The fix for this was released in https://github.com/fabric8io/fluent-plugin-kubernetes_metadata_filter/pull/317 and in the fluent/fluentd-kubernetes-daemonset:v1.14.6-debian-elasticsearch7-amd64-1.1 container image.
Conclusion
For me, this was a rather exciting investigation, and the lesson learned – don’t forget to update your software 🙂
References
- Ninja Van Tech found that they are missing logs in GKE.
- Fluentd is skipping logs in the Kubernetes Github issue.
- /var/log/containers/*.log and /var/log/pods/<podUID>/<containerName>_<instance#>.log Github issue.
Kubelet code:
- https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/kuberuntime/kuberuntime_sandbox.go#L110-L111
- https://github.com/kubernetes/kubernetes/blob/242a97307b34076d5d8f5bbeb154fa4d97c9ef1d/pkg/kubelet/api/v1alpha1/runtime/api.proto#L534-L544
- https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/kuberuntime/kuberuntime_container.go#L264-L279