Introduction
A while back, my colleagues and I, ran a Kubernetes cluster with large nodes with about 300-400 containers running on each node. It was running on Linux CentOS 7, with a linux-3.10.0-1160.88.1.el7 kernel. And after about three years of mostly stable cluster, our nodes started randomly freezing.
It usually started in the morning, and we would see an utterly locked-up system. Kubernetes components were still running, kubectl get nodes, and would report Ready, but the node would behave rather strangely. The CPU Load Averages would go thru the roof.

PID 1 went to uninterruptible sleep state
The annoying part is that I couldn’t ssh into a machine, but I could access it if I had an old ssh connection. Investigating the problem, we saw that `pid 1` is in the “D” – uninterruptible sleep state:
$ ps faux | grep " D"
root 3828430 0.0 0.0 0 0 ? D 07:15 0:00 \_ [kworker/41:2]
root 2984646 0.0 0.0 0 0 ? D 08:47 0:00 \_ [kworker/27:1]
root 1 11.1 0.0 206572 17996 ? Ds May02 326:25 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 968 2.5 0.0 183056 121804 ? Ds May02 73:22 /usr/lib/systemd/systemd-journald
root 3476 1.1 0.0 27296 2648 ? Ds May02 34:18 /usr/lib/systemd/systemd-logind
root 1008604 0.0 0.0 112812 980 pts/0 S+ 13:53 0:00 | \_ grep --color=auto DThe only thing that would fix this problem – is rebooting the machine.
Debugging the problem
After a week of these random node lockups and hard reboots, looking at random metrics and random stuff – like looking into newly scheduled containers before lockups, we finally found a good way to investigate the problem. Credit to High System Load with Low CPU Utilization on Linux? for helpful information on debugging systems like that and general information on this topic.
It turns out you need to look into the stack traces because, most likely, the kernel is waiting on the lock. You can get stack traces in Linux by executing cat /proc/PID/stack. In our case, this would give us the following stack trace:
$ cat /proc/1/stack
[<ffffffff856c828e>] wait_rcu_gp+0x5e/0x80
[<ffffffff8576286b>] synchronize_sched+0x3b/0x60
[<ffffffff858488fc>] mem_cgroup_start_move+0x1c/0x30
[<ffffffff8584c2d5>] mem_cgroup_reparent_charges+0x65/0x3c0
[<ffffffff8584c7e4>] mem_cgroup_css_offline+0x84/0x170
[<ffffffff85732baa>] cgroup_destroy_locked+0xea/0x370
[<ffffffff85732e52>] cgroup_rmdir+0x22/0x40
[<ffffffff85868b6c>] vfs_rmdir+0xdc/0x150
[<ffffffff8586e711>] do_rmdir+0x1f1/0x220
[<ffffffff8586f9a6>] SyS_rmdir+0x16/0x20
[<ffffffff85dc539a>] system_call_fastpath+0x25/0x2a
[<ffffffffffffffff>] 0xffffffffffffffffIn this case, it seems that the PID 1 process is trying to delete memory cgroup, and the process is waiting for a “rcu_gp” (read-copy-update grace period) to complete, which is a synchronization mechanism used in the kernel.
If you look at the kernel code for these functions, you can see that cgroup_rmdir takes a cgroup mutex. See the following code:
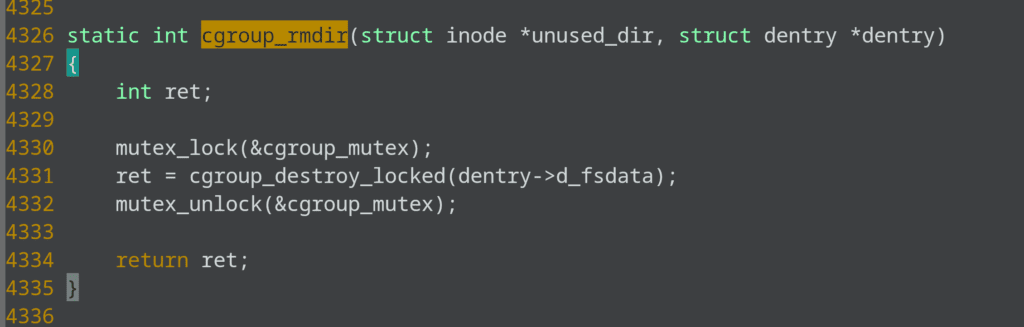
and down the line calls mem_cgroup_start_move, which waits on rcu:
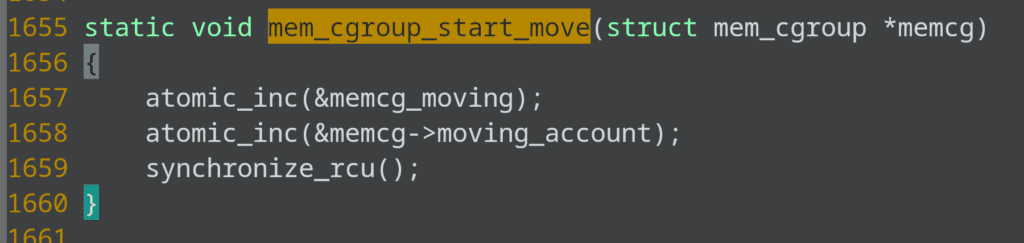
So the system is locked up.
The solution to lock-ups
After searching the internet, the only thing related I found is Possible regression with cgroups in 3.11 kernel mailing list thread. In which the user talks about a similar problem. This gave us the idea that this bug is already fixed but not back-ported in CentOS 7.
So I looked into the Rocky 8 kernel, and the memory cgroup code changed quite a bit.
Because migration from Centos 7 to Rocky 8 is quite challenging, we quickly fixed it by using 5.4 kernel from ELrepo. And after installing the new kernel, we haven’t seen the problem since.